Verbranched, vermerged und zugenäht – Git-Branching Modelle kurz vorgestellt
Erschienen im KaffeeKlatsch, September/Oktober 2019
Dank der Flexibilität von Git gibt es nicht “das Verfahren”, wie Feature-Branches, Releases und die Pflege mehrerer Alt-Versionen im Repository abgebildet werden. Daher haben sich einige Standard-Workflows herausgebildet. Der hier vorliegende Vergleich von drei sehr unterschiedlichen Workflows hilft dabei, die passende Wahl für sein eigenes Projekt zu treffen.
Warum gibt es nicht eine einzige Lösung für das Problem? Weil es in jedem Projekt neben dem reinen Code sehr unterschiedliche nicht-technische Rahmenbedingungen gibt. Viele davon beeinflussen direkt den Umgang mit der Versionskontrolle, werden aber bei der Darstellungen vom “idealen Workflow” meist nicht erklärt.
Das markanteste Beispiel für eine solche Rahmenbedingung ist folgendes:
Liefert das Projekt eine Web-Anwendung aus, eine “traditionelle”, auf dem PC installierte Anwendung oder eine Library. Bei einer Web- oder Mobil-Anwendung ist immer nur eine Major-Version produktiv – es gibt also keine Pflege von älteren Versionen. Bei einem Produkt, das der Kunde selbst installiert, gibt es in der Regel neben der aktuellsten Version noch eine oder mehrere ältere Major-Versionen für Bugfixes oder zumindest Security-Fixes. Und schon hat man in Git mehrere parallele Haupt-Entwicklungslinien, die dennoch synchronisiert werden müssen. Bei einer Library ist es ebenso üblich, mehrere Major-Versionen über einen relativ langen Zeitraum zu unterstützen.
Weitere Rahmenbedingungen sind:
-
Parallele Arbeiten: Wie viele Leute arbeiten parallel an wie vielen unabhängigen Features, Bugfixes oder Support-Versionen? Je höher die Parallelität ist, desto wichtiger aber auch schwieriger ist es, den Haupt-Entwicklungszweig stabil zu halten. Dadurch entscheidet sich letztlich, ob Continous Integration in Reinkultur oder doch Feature-Branches sinnvoll sind.
-
Code-Umfang: Bei einer großen Codebasis kann die Entwicklung vieler paralleler Features dennoch problemlos sein, weil sich die Entwickler in der Regel nicht in die Quere kommen. Es sei denn, es gibt zentrale Stellen, an denen jeder Entwickler gleichzeitig arbeitet.
-
Release- und Freigabe-Prozesse: Dauert das Bauen und Freigeben eines Releases nur kurze Zeit oder – inklusive Bugfixes – doch so lange, dass de-facto jeder Release ein eigener Haupt-Entwicklungszweig ist?
-
Team-Struktur: Sitzen alle Committer im selben Raum und haben kurze Kommunikationswege oder erfolgt sämtliche Kommunikation über E-Mail Listen? Handelt es sich um Entwickler, die Vollzeit an dem Projekt arbeiten oder um OpenSource-Entwickler, die in ihrer Freizeit je nach Lust und Laune Features fertigstellen?
-
Zugriffsrechte/Rollen: Können alle Entwickler in den Hauptbranch committen oder nur ausgewählte Personen? Daran hängen ggf. auch Review-Prozesse.
-
Selektive Feature-Freigabe: Ein sehr wichtiger Punkt. Wann ist ein Feature so akzeptiert, dass es geliefert wird? Wenn z.B. im Sprint-Review alle Features demonstriert werden, sind sie schon im Hauptbranch integriert. Wenn ein Feature so schlecht abschneidet, dass es entfernt werden muss, kann das wegen der gegenseitigen Abhängigkeiten sehr aufwendig sein.
Dies ist bei weitem keine vollständige Aufzählung aller Einflüsse auf das Branching-Modell oder – umgekehrt – auf die das Branching-Modell Einfluss hat. Aber klar ist, dass die rein technischen Aspekte der Versionsverwaltung nicht den Ausschlag geben dürfen, sondern die sozialen/politischen Aspekte des Projektes – auf der Grundlage der technischen Möglichkeiten. Es gibt daher keine Patentlösung, sondern nur Bausteine und Muster, aus denen eine passende Lösung entsteht.
In den folgenden Abschnitten werden vier Branching-Modelle bzw. Projekte vorgestellt, bei denen diese Rahmenbedingungen sehr unterschiedlich sind.
PostgreSQL
PostgreSQL1 ist eine OpenSource-Datenbank mit einer BSD/MIT ähnlichen
Lizenz. Als Versionsverwaltung diente bis 2010 CVS, erst seit September
2010 kommt Git zum Einsatz. Der Artikel zur Umstellung2 enthält die
treffende Bemerkung […]sticking with our “conservative approach” to source
control[…]
. Das GitHub-Repository dient nur als Mirror – es gibt
keine Pull-Requests, Issues etc. Die Entwicklung erfolgt vollständig über
eine E-Mail Liste, auf der die Patches verbreitet und diskutiert werden. Obwohl
PostgreSQL fünf Support-Versionen pflegt, werden Features und Bugfixes nicht
gemerged, sondern in die Support-Branches mit git cherry-pick übernommen
(siehe Abbildung 1).

Außer diesen Haupt-Branches enthält das Hauptrepository keine
Feature-Branches. Es gibt – gemessen an der Größe des Projektes und am Alter
der Codebasis – nur relative wenige Committer (etwa 50, davon 28 aktive im
letzten Jahr). Die tatsächlichen Urheber der Patches werden – entgegen den
Git-Konventionen – nicht in den Feldern Author und Committer im Commit
sondern nur im Commit-Kommentar vermerkt. Je nach Committer geschieht das
unformal (z.B. “Patch by Name
Der Release-Prozess ist aus Sicht des Branching-Modells auch sehr einfach: In einem Commit werden ein paar Versionsnummern angepasst und direkt committed – fertig (siehe Abbildung 2).
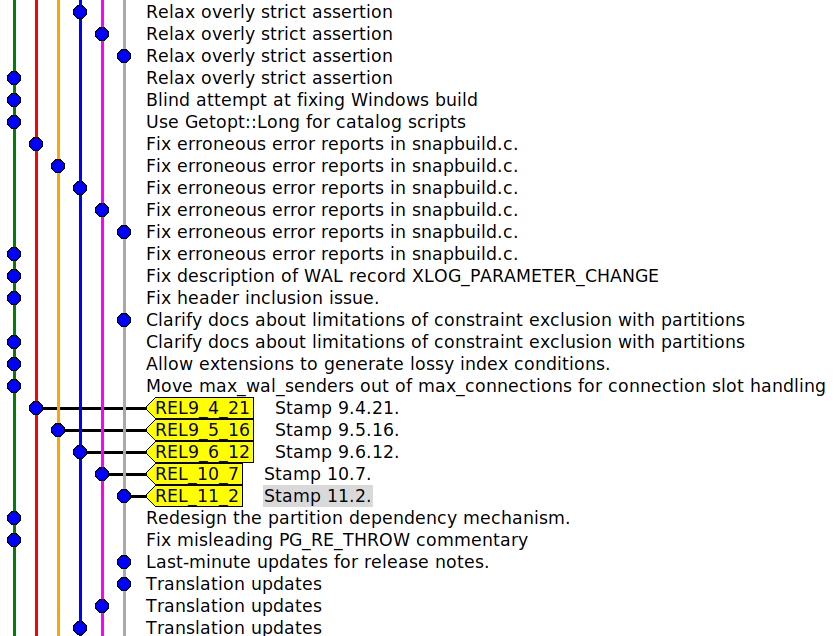
PostgreSQL ist also bewusst völlig Git-Agnostisch – selbst so einfache Dinge wie die Unterscheidung “Author” und “Committer” werden nicht verwendet. Die Entwicklung ist streng linear und extrem simpel. Allerdings erfordert das Back-Patching von Bugfixes Disziplin.
Git-Flow
“Git-Flow”3 ist kein Projekt sondern der Name eines Branching-Modells, das erstmals von Vincent Driessen beschrieben wurde.
Im Kern gibt es die Unterscheidung von permanenten Integrationsbranches (master, develop, ggf. auch support/* als Erweiterung) einerseits und temporären Branches (feature/*, bugfix/*, release/*, hotfix/*) andererseits
Die Entwicklung eines Features findet in einem Feature-Branch statt (z.B. feature/xyz), der von develop ausgeht und nach Abschluss des Features wieder in develop integriert wird. Die Integration kann durch einfaches Mergen, Rebasen oder Rebase + Merge stattfinden (siehe Abbildung 3).

Insbesondere die letzte Methode erzeugt eine übersichtliche Historie, in der die Features gut sichtbar bleiben und ggf. durch einen Revert des Merge-Commits wieder entfernt werden können.
Sind die Features für einen Release fertig, so wird aus develop ein temporärer release/1.2.3 Branch abgezweigt. Der Branch dient zur Stabilisierung des Release, ohne die Arbeit in develop zu behindern. Nach der letzten Änderung wird die Versionsnummer angepasst und das Ergebnis sowohl nach master als nach develop gemerged Der Merge-Commit auf master erhält noch ein Versions-Tag (siehe Abbildung 4). Der Merge nach develop garantiert, dass die Bugfixes, die den Release stabilisieren, auch in die normale Entwicklung zurückfließen. Der Release-Branch wird zum Abschluss gelöscht.

Eine Variante des Release-Branches ist der Hotfix-Branch: Wird im letzten Release ein schwerwiegender Fehler entdeckt, kann man nicht auf den nächsten Release warten. Daher zweigt der Hotfix-Branch nicht aus develop ab, sondern aus master, dem letzten Release (siehe Abbildung 4). Ansonsten ist das Verfahren dasselbe wie beim Release-Branch.
Es gibt für Git-Flow Tool-Unterstützung: Die Eclipse-IDE stellt Kontext-Menüs für das Anlegen der Branches bereit. Für die Kommandozeile gibt es das Git-Plugin gitflow-avh4, welches in “Git for Windows” schon integriert ist.
Das Ziel von Git-Flow ist die Entkoppelung auf mehreren Ebenen:
-
Ein Feature-Entwickler kann in Ruhe und ohne Störung sein Feature entwickeln und zu Zeitpunkten, die ihm passen mit develop abgleichen oder integrieren.
-
develop sollte in der Regel stabil sein. Wenn er aber mal instabil ist, so kann auf den Feature-Branches noch weiterentwickelt werden, bis das Problem gelöst ist.
-
Releases und Hotfixes können ebenfalls asynchron zur Feature-Entwicklung durchgeführt werden.
Die Stärken von Git-Flow sind ein überschaubarer Commit-Graph (bei der “rebase + merge” Variante), wenige Blockaden der Entwickler und die Tool-Unterstützung. Aber das nachträgliche Entfernen von Features ist nur schwer möglich, da nach dem Mergen des Features in develop die nachfolgenden Features implizit darauf aufbauen.
OneFlow
“Git-Flow” zieht dennoch Kritik auf sich. In “GitFlow considered harmful”5 kritisiert Adam Ruka vor allem zwei Dinge:
-
Die komplizierte, nicht-lineare Historie, wenn Entwickler Features nur mit
git merge --no-ffnach develop mergen. -
Die Unterscheidung zwischen master und develop sei unnötig.
Daraus entwickelte er das “OneFlow” Branching Modell6. Darin beschreibt er die drei schon erwähnten Methoden, einen Feature-Branch wieder in den Hauptzweig zu integrieren, der aber master heißt. Allerdings können dieselben Mechanismen auch in Git-Flow verwendet werden. Interessanter ist das Erstellen von Releases: zwar gibt es auch einen release/x.y.z Branch, der wie in Git-Flow nach Abschluss des Releases in den Haupt-Zweig gemerged wird. Im Unterschied zu Git-Flow wird der letzte Commit des Release-Branch mit der Versionsnummer getagged (siehe Abbildung 5). Hotfixes setzen ggf. auf diesem Tag auf wie im Bild zu sehen ist.

Allerdings gibt es nun keinen Branch mehr, der den aktuellsten stabilen Stand kennzeichnet. Dafür schlägt Adam Ruka als Variante vor, den Hauptentwicklungszweig doch wieder wie bei Git-Flow develop zu nennen und den letzten Release mit dem master Branch zu markieren. OneFlow unterscheidet sich dann aber nicht mehr viel von Git-Flow – es ist eher eine Variante des mit starken Worten kritisierten Git-Flow.
OneFlow ist etwas, aber nicht entscheidend einfacher als Git-Flow. Es verliert aber im Gegensatz zu Git-Flow die Möglichkeit, anhand eines durchgehenden master Branches die Release-Stände einfach nacheinander aufzulisten. Wie bei Git-Flow können einmal integrierte Features nur schwer selektiv entfernt werden.
git.git
Der letzte vorgestellte Workflow stammt vom Git-Projekt selbst. Git ist in
vielen Punkten mit PostgreSQL vergleichbar: Die Entwicklung des OpenSource-
Projektes erfolgt ausschließlich über eine E-Mail Liste. Die Entwickler
arbeiten räumlich verteilt und gehören keiner gemeinsamen Organisation
oder Firma an. In der E-Mail Liste werden Patches geposted, diskutiert und
verbessert. Das danach folgende Branching-Modell verfolgt allerdings einen
grundlegend anderen Ansatz – eine vereinfachte Form ist im Manual unter git help workflows dokumentiert7.
Neue Topics (so nennt dieser Workflow Features und Bugfixes) basieren auf dem letzten stabilen Branch (meist “master”, s.u.). Zuerst werden sie nur als Patches auf der Mailing-Liste diskutiert und verbessert. Erst nach einer Konsens-Findung greift der Maintainer die Patches eines Topics auf, stellt sie als Branches zur Verfügung und merged sie – nach und nach – in verschiedene Integrationsbranches. Die Integrationsbranches sind “gestaffelt” – jeder Integrationsbranch enthält neben den eigenen Topics indirekt alle Commits der jeweils stabileren Stufe(n). Es bildet sich also eine Teilmengen-Relation zwischen den Branches:
-
pu (Proposed Updates) ist der instabilste Branch – er enthält unfertige Features und dient der frühen Integration. Dieser Branch wird oft zurückgesetzt und komplett neu aufgebaut. Dadurch können Features auch wieder entfallen, wenn sie z.B. nicht weiter verfolgt werden.
-
next enthält nur Features, die prinzipiell “akzeptiert” und in gutem Zustand sind, aber noch instabil sind oder noch ein wenig Politur benötigen. Dieser Branch wird einmal pro Release zurückgesetzt. Features in next sind – in der Regel – Teil des nächsten Releases.
-
master ist der stabilste Branch – er enthält nur hochwertige und akzeptierte Features und Bugfixes. Aus diesem Branch wird der nächste Release erstellt.
-
maint dient der Pflege älterer Versionen – daher empfängt er nur Bugfixes.
Das Git-Branching Modell arbeitet intensiv mit Merge-Commits. In den folgenden Bildern sind Merge-Commits von “anderen” Features mit einem kleinen Pfeil gekennzeichnet.
Wie schon erwähnt, basiert ein neues Feature (im Gegensatz zu einem Bugfix) auf dem jeweils aktuellen master Branch (siehe Abbildung 6).
Da die Patches per E-Mail übertragen werden, können Sender und Empfänger (der Git-Maintainer) durchaus einen anderen Stand haben – implizit findet also eine Art “Rebase” statt. Nach der Diskussion auf der E-Mail Liste wird das Feature zusammen mit anderen Features in den pu Branch gemerged. Der pu Branch wird nicht nur erweitert, sondern auch regelmäßig weggeworfen (siehe graue Lebenslinien im Bild) und aus next neu erstellt. Dabei können Features bewusst wieder entfernt werden, weil sie z.B. nicht mehr weiter verfolgt werden oder selbst für pu zu unreif sind. Wird ein Feature in pu verbessert, so wird der gesamte bisherige Feature-Branch weggeworfen, neu eingespielt und in den nächsten neu erstellten pu Branch gemerged. Auch hier findet implizit ein Rebase statt.

Die nächste Stufe erreicht das Feature, wenn es in den next Branch gemerged wird (siehe Abbildung 7 oberer Teil). In dieser Phase werden weitere Änderungen am Feature nicht mehr durch Wegwerfen des gesamten Branches durchgeführt, sondern als Patches im Branch, die dann auch wieder nach next gemerged werden. In jedem Fall wird der pu Branch – aufbauend auf dem aktualisierten next – neu erstellt.

Wenn das Feature abgeschlossen und stabil ist, erfolgt der Merge nach master (siehe Abbildung 7 unterer Teil). Anschließend erfolgt ein “Sync” Merge von master nach next. Jetzt ist das Feature sicher im nächsten Release enthalten.
Dies ist der Workflow, wie er in 7 beschrieben ist, aber Git selbst weicht davon in Details ab. Für das Verständnis des Verfahrens an sich ist daher der nächste Absatz und das nächste Bild nicht wichtig und kann übersprungen werden. Sie sind aber z.B. nützlich, wenn Sie selbst bei Git einen Patch einbringen und den Ablauf verfolgen möchten.
Ein neuer pu Branch wird tatsächlich nicht direkt aus next erstellt, sondern aufbauend auf dem jeweils aktuellen master. Die Feature-Branches, die in next aber noch nicht in master sind, werden also nochmal gemerged (siehe Abbildung 8). Das heißt, dass die meisten “gereiften” Features immer in zwei Branches gemerged wurden: Entweder in pu und next oder in master und next.

Bugfix Branches müssen – im Gegensatz zu neuen Features, auf dem Branch der ältesten Version erstellt werden, die unterstützt werden soll (siehe Abbildung 9). Sie werden zuerst nach next gemerged, um im aktuellen Entwicklungszweig eventuelle negative Auswirkungen festzustellen. Danach kommt der Bugfix in master und erst zum Schluss in die Maintenance Branches.

Schon die schematische Darstellung des Git Workflow zeigt, dass er schwer zu durchschauen ist. Die Branch-Pflege ist aufwendig, unübersichtlich und eine visuelle Kontrolle mittels graphischer Darstellung ist de-facto unmöglich. Durch das neu Bauen des pu Integrations-Branches werden zwar textuelle Konflikte gefunden. Logische Konflikte (z.B. benennt Feature A eine Variable um, Feature B erstellt eine neue Funktion/Klasse/Datei, in der noch der alte Name verwendet wird) benötigen zusätzliches Tooling, um bei jedem Neubau diese Änderungen mitzuziehen. All das erfordert wasserdichtes, narrensicheres Tooling.
Der Git-Workflow erlaubt allerdings eine bessere Feature-Selektion als die anderen Verfahren: Features in pu können einfach so gelöscht werden, auch Features in next können noch leicht entfernt werden.
Fazit
Branching-Modelle sind manchmal ein hitziges Diskussionsthema. Aber “den” Workflow, der für jedes Projekt passt, gibt es nicht. Da aber – bis auf Git selbst – der Zweck des Projektes nicht Versionskontrolle sondern etwas anderes ist, sollte das Branching Modell wenig mentale Kosten verursachen und möglichst einfach sein. PostgreSQL zeigt das als Extrembeispiel sehr deutlich. Im typischen Enterprise-Projektumfeld empfiehlt sich der Git-Ansatz nur, wenn extrem viele Leute am Projekt arbeiten und Features regelmäßig bei Sprint-Abnahmen so durchfallen, dass sie spät im Entwicklungszyklus wieder entfernt werden müssen. In diesem Fall ist es aber vermutlich für alle Beteiligten einfacher, das Umfeld zu ändern. “Git-Flow” und “OneFlow” sind letztlich sehr ähnlich und – bei kurzem Nachdenken – das, was viele Projekte im Enterprise Umfeld prinzipiell auch schon tun – nur ohne die Terminologie zu verwenden.
In allen Fällen darf man Branching-Modelle nicht als “das letzte Wort” betrachten, sondern eher als Baukasten oder Pattern, die für den jeweiligen Fall angepasst werden.
Kurzbiografie

-
PostgreSQL - now on git!, Magnus Hagander, 2010-09-21 ↩︎
-
A successful Git branching model, Vincent Driessen, 2010-01-05 ↩︎
-
gitflow-avh, GitHub ↩︎
-
GitFlow considered harmful, Adam Ruka, 2015-05-03 ↩︎
-
OneFlow - a Git branching model and workflow, Adam Ruka, 2017-04-30 ↩︎